HTTP WebCache Topologies
(Second part of the previous posting on Distributed Web Caching)
Caching Topologies
Some protocols are oriented towards a particular kind of deployment, e.g ICP is oriented towards a hierarchical model of deployment while CARP is oriented towards a flat deployment. Some protocols allow easy addition of new caches to the cluster while some like WCCP has inherent restrictions on the number of caches that can serve at a single level. A few of the protocols have restrictions as the the environments in which they can be deployed, and are different from the other caches. For e.g WCCP can only be deployed as an Intercepting Proxy and requires specialized equipment or operating system support to function. It is also limited to subnets in terms of the cache membership. On the other hand ICP requires use of UDP which may prevent it from operating across fire-walls. This survey will also document the common deployment scenarios for each protocol. Caching meshes can be formed by using any of the these protocols so as to provide a faster service to the client and lighter load on the content servers. This survey will document the restrictions and deficiencies with each protocol with regards to the deployment of cache meshes and mesh topologies for each where they can be used effectively.
A hierarchical topology
In a hierarchical topology[29] without support for cache cooperation protocols, the caches are placed at multiple levels of the network. The proxies are arranged in a tree structure with each Proxy having at most one parent, and zero or more children. When a document is requested, the request travels up the chain culminating in the server that is ready to serve a non stale copy of the response object. A parent can never query its children.
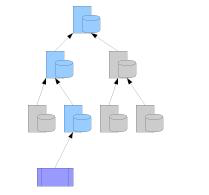
Advantages
- Traffic is reduced at successive levels of the tree
Disadvantages
-
For effective hit rate at upper levels, disk space required at upper nodes is quite large.
-
Hit rates at root servers are very low.
A hierarchical cooperative topology
In this topology[29], the Proxy Servers with the same parent are considered peers, and they communicate among themselves as to the location of the cached object. ICP and its successors are used for communication between the caches.
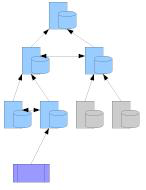
Advantages:
-
Better cache hit rate
-
Reduces the load on root servers
Disadvantages
-
The cache must maintain information about the siblings to be able to query them. This is error prone and unwieldy.
-
Increased Latency due to waiting for siblings to respond.
A distributed caching topology
In a distributed caching topology[28], caches are arranged such that a client can contact a single cache which is closest to it, and that cache will directly contact the content server. This scheme avoids the use of servers at the root and upper levels of hierarchy to resolve the requests and store cached documents. Instead only leaf caches are responsible for retrieving and storing the objects while the upper caches maintain the information about contents of all children. When a leaf cache retrieves an object, An advertisement is sent up the tree through its parent. The advertisement recursively travels to the root node. When one of the leaf caches are queried for an object, it recursively looks up its parents until it either finds a (grand)parent that contains information about where the cache is located, and forwards the request to that cache or it assumes that the object is not cached. In that case the object is retrieved directly by that node.
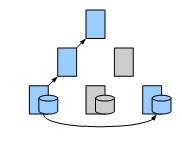
Advantages:
-
Removes the requirement of storage at upper levels yet retains the advantage of lookup.
-
Removes the management problems with maintaining sibling information.
-
Latency for miss is reduced as a cached object is at most one hop away.
Disadvantages:
- The leaf caches become heavily loaded.
A partitioned URL name space topology
In a partitioned URL name space topology, the clients may contact different proxies depending on the type of the URL requested. Thus rather than geographical partitioning this facilitates content based or origin server based partitioning of the load.
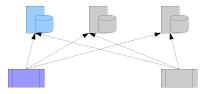
Geographical Server Push Caching
Geographic Server Push Caching[26] is used to make sure that the content is close to the clients that request it. It is still in research, and may be used by Content Delivery Networks. The server keeps track of its own load factor, and when a push-threshold is reached, the most accessed content is pushed to the Server from where the most request came from based on the past access history. A push caching protocol extension to HTTP is detailed here [27]. Push Caching is used especially when the bandwidth available to the end user is limited or the end user is on a mobile or wireless network.
Advantages:
-
Reduces traffic
-
Reduces Latency
Disadvantages:
- If the content is not requested frequently, the bandwidth is wasted.
Adaptive Web Caching
In Adaptive Web Caching[31], the Proxy Servers join and part from dynamically formed overlapping groups. This is accomplished using Cache Group Management Protocol. The look up of the content is accomplished using Content Routing Protocol. These protocols were discussed earlier. Adaptive Web Caching was primarily intended to tackle hot spots and flash crowds.
Cache Routing Table approach
Used in Cachemesh[32], This approach relies on cache servers periodically exchanging cache routing information and pre-computing the cache routing table. The cache routing table contains the information on who the owner will be for any given URL. (In this respect it is similar to CARP). When a Proxy Server receives a request, it looks up the cache routing table and forwards the request to the Server returned. In this system there is no hierarchy of caches. (Each cache is one hop away from any other.)
En-Route Caching using Load Diffusion
As implemented in WebWave[33], A set of co-operating Caches are organized in a routing tree. Caches periodically exchange the load information between themselves. An object can be cached any where en route to the origin server. An object copy is only created when a parent notices that a child is lightly loaded compared to the parent. Conversely when a child may decide to delete some of its cached objects if the parent becomes lightly loaded asymmetrically.
Peer to Peer DHT Overlay Network
In Peer to Peer caching scheme (the example discussed here is Backslash[35]) each node runs a WebServer as a Surrogate and a DNS server. When a node is about to be overloaded, it rewrites the content it serves to direct the traffic away from it and to another peer. This rewrite takes advantage of DNS lookup so that the requests to the embedded content are directed to a different node based on the hash of the lookup URL. When the peer is completely overloaded, it makes use of HTTP Redirect to make the client issue a second request to another Surrogate peer. Once a node has decided to serve a request, it acts as a gateway into the Distributed Hash Table based mirroring using the same peers. Another example is Squirrel[37], Coral Content Delivery Network running on Planet Lab uses a similar technique called Distributed Sloppy Hash Table[39] for lookup.
Advantages:
- No single point of failure
Disadvantages:
- DHT Overlays have poor locality
Peer to Peer Unstructured Overlay Network
In Unstructured Overlay Networks, the peers are organized to a Small World Network[40]. Taking the example of dijjer[41], the peers dynamically organize themselves to a mesh. Each peer has a hash calculated from its IP address and port. The data is stored in blocks, and each block has an associated hash. The nodes tend to store data with a hash value that is closest to their own hash. When a request to a URL is made by an HTTP client, the node will contact the origin server for a HEAD request obtaining the size, last modified time and if the object can be cached. The hash is calculated using the above information. Once the hash is calculated, the node will try to find another node with a hash value closer to the data hash than itself. If it finds none, then it retrieves the block and caches it. If it finds another node with a hash closer to the data hash, then the request is forwarded to that node. A different approach is taken by NoTorrent[42]. It is a system that adapts peer to peer BitTorrent protocol to web caching. It includes a torrent tracker which keeps track of which nodes have downloaded which ranges of files, and this information is shared with other nodes on request. The NoTorrent nodes uses this information to contact other nodes that have a copy of the required file range.
References
[1] RFC 2616 Fielding, et al. http://www.w3.org/Protocols/rfc2616/rfc2616-sec13.html
[2] RFC 2186 http://www.ietf.org/rfc/rfc2186.txt
[3] RFC-DRAFT http://icp.ircache.net/carp.txt
[4] RFC http://www.squid-cache.org/CacheDigest/cache-digest-v5.txt
[5] RFC 2756 http://www.faqs.org/rfcs/rfc2756.html
[6] RFC-DRAFT http://tools.ietf.org/id/draft-wilson-wrec-wccp-v2-01.txt
[7] RFC 3040 http://www.faqs.org/rfcs/rfc3040.html
[8] RFC 3507 http://www.icap-forum.org/documents/specification/rfc3507.txt
[9] RFC 3229 http://www.ietf.org/rfc/rfc3229.txt
[10] cache-channels http://ietfreport.isoc.org/all-ids/draft-nottingham-http-cache-channels-01.txt
[11] HTTP 1.0 http://www.ietf.org/rfc/rfc1945.txt
[12] HTTP 1.1 http://www.ietf.org/rfc/rfc2068.txt
[13] caching problems http://www.networksorcery.com/enp/rfc/rfc3143.txt
[14] cache-protocols http://www.web-cache.com/Writings/protocols-standards.html
[15] ICP Applications http://www.ietf.org/rfc/rfc2187.txt
[16] http://www.csd.uoc.gr/~hy558/papers/wang99survey.pdf
[17] http://www.isoc.org/inet98/proceedings/1k/1k_1.htm
[18] http://forskningsnett.uninett.no/arkiv/desire/sumreport/sumreport.html
[19] http://2002.iwcw.org/papers/18500200.pdf.
[20] http://www.squid-cache.org/mail-archive/squid-users/199807/0010.html
[21] CRISP http://www.cs.duke.edu/ari/cisi/crisp-recycle/crisp-recycle.html
[22] HTTP Notify http://www.w3.org/TR/WD-proxy
[23] PBV http://www.usenix.org/publications/library/proceedings/usits97/krishnamurthy.html
[24] PBI http://www.research.att.com/~bala/papers/psi-www7.ps.gz
[25] HTTP Distribution and Replication Protocol http://www.w3.org/TR/NOTE-drp-19970825.html
[26] Push Caching http://www.eecs.harvard.edu/~vino/web/hotos.ps
[27] Push Caching Protocol http://www.cs.uwaterloo.ca/~alopez-o/cspap/cache/Overview.html
[28] http://www.dstc.qut.edu.au/MSU/staff/povey/papers/dcache.ps
[29] http://www.codeontheroad.com/papers/HarvestCache.pdf
[30] http://www.iwcw.org/1998/25/3w3.html
[31] Web Caching and Its Applications - Nagraj http://books.google.com/books?isbn=1402080492
[32] Cachemesh http://workshop97.ircache.net/Papers/Wang/wang.txt
[33] http://sys192.cs.washington.edu/Related/xdcs.ps
[34] http://irl.cs.ucla.edu/AWC
[35] http://www.cs.rice.edu/Conferences/IPTPS02/176.pdf
[36] http://www.ics.uci.edu/~taylor/documents/2002-REST-TOIT.pdf
[37] http://research.microsoft.com/~antr/PAST/squirrel.pdf
[38] http://www.coralcdn.org/overview/
[39] DSHT http://www.coralcdn.org/docs/coral-iptps03.pdf
[40] http://en.wikipedia.org/wiki/Small_world_network
[41] http://code.google.com/p/dijjer/
[42] http://www.howardissimo.com/notorrent/
[43] http://www.cs.wisc.edu/~cao/papers/summary-cache/
[44] http://www.hpl.hp.com/techreports/1999/HPL-1999-109.ps
[45] http://www.sunlabs.com/features/lockss/index.html
[46] HQCM http://ieeexplore.ieee.org/xpl/freeabs_all.jsp?arnumber=801214
[47] WPAD http://www.ietf.org/proceedings/99nov/I-D/draft-ietf-wrec-wpad-01.txt
[48] http://www.dyncorp-is.com/darpa/meetings/ngi98oct/Files/Zhang%20NGI-final.ppt
[49] DOCP http://www.hpl.hp.com/techreports/1999/HPL-1999-109.html
[50] http://www-sor.inria.fr/projects/relais/index.html.en