Distributed HTTP Caching Mechanisms
This was a project report I produced for the distributed computing class during my masters. I asked for this topic since I was already working on distributed HTTP cache protocols ICP and CARP at Sun Microsystems.
Introduction
The world wide web functions as a distributed system. The servers and clients may be distributed in diverse geographically distant locations, and the communication between them is orchestrated using HTTP as the communication protocol. Often a request from a client to a server or a response the reverse way have to pass through multiple intermediaries (variously called proxies, reverse-proxies, load balancers, edge servers etc.). In order to efficiently support this complex system, the HTTP protocol documents various methods using which an intermediary can determine the freshness of a requested resource. Based on the freshness thus computed, the intermediary can determine if a newer copy needs to be fetched from the upstream or to serve it from the local cache.
Caching from the early times
From the outset when web was created, it was realized that for the distributed system to be effective, it would have to rely on intermediaries that replicated or cached the content so as to lessen the load on both the network and the endpoint servers. The earliest automatic caching and replication was done by rewriting the HTML using CGI scripts that forwarded the subsequent requests to the local cache. This was the main type of cache for HTTP 0.9 version of protocol e.g Lagoon Cache. The caching mechanisms included with the HTTP protocol were incorporated first by CERN HTTPd in 1993. This later was incorporated into the HTTP 1.0 protocol description RFC 1945[11] in 1996. The next iteration of HTTP protocol HTTP 1.1 RFC 2068[12] and RFC 2616 in 1997 laid the foundation of the distributed cache protocols which are in use today.
Caching Now
However, the RFC 2616 for HTTP1.1 was written during the time when most of the web was static. Thus it deals with the pages as the smallest unit. However, post the year 2000, this assumption has begun to change in a big way with Blogs, Wikis, Mailing Lists, News Portlets and others where the unit of trackable change is smaller than a single page. Another important change post the year 2005 was the introduction of AJAX which has made caching more harder than before. One attempt to deal with the above changes has been the HTTP delta encoding[9]. Another has been the cache-channels draft RFC[10]. Recently Applications have started becoming REST[36] compliant which has also meant that HTTP caching architecture plays a big role in these applications.
Distributed Caching
One aspect of this distributed system is that the caches co-ordinate among themselves to determine if the requests can be fulfilled without contacting the upstream servers. In this way the traffic to the original content servers are minimized. A host of cache communication protocols are used for this purpose depending on the type of caching needed and the network topology.
Some of these cache protocols as specified in RFC 3040[7] are: ICP[2] CARP[3] Digests[4] HTCP[5] WCCP[6] other mechanisms for cooperative caching include ICAP[8], non HTTP mechanisms like Memcached and others. This survey documents and compares the characteristics of various caching protocols.
Some protocols are oriented towards a particular kind of deployment, e.g ICP is oriented towards a hierarchical model of deployment while CARP is oriented towards a flat deployment. Some protocols allow easy addition of new caches to the cluster while some like WCCP has inherent restrictions on the number of caches that can serve at a single level. A few of the protocols have restrictions as the the environments in which they can be deployed, and are different from the other caches. For e.g WCCP can only be deployed as an Intercepting Proxy and requires specialized equipment or operating system support to function. It is also limited to subnets in terms of the cache membership. On the other hand ICP requires use of UDP which may prevent it from operating across fire-walls. This survey will also document the common deployment scenarios for each protocol.
Caching meshes can be formed by using any of the these protocols so as to provide a faster service to the client and lighter load on the content servers. This survey will also document the restrictions and deficiencies with each protocol with regards to the deployment of cache meshes and mesh topologies for each where they can be used effectively.
Why Cache
-
Caching reduces the latency for an individual user
-
Reduces the load on the server
-
Reduces the traffic in the network
-
Provides redundancy and fault tolerance for servers
Types Of Caches
There are essentially three types of HTTP Caches
-
A Browser Cache maintains a local copy of object at the client machine. This reduces the need to re-retrieve the object when the same object is a part of multiple documents. It also avoids the need for traffic when a page has to be viewed again.
-
A Proxy Cache is maintained at the Proxy Server that the HTTP request passes through. There may be multiple Proxy Servers or none at all depending on the configuration of the browser and depending on interception of HTTP Requests are done. A normal Proxy Server has to be configured in the HTTP Client to be added as an intermediary in the HTTP Request path, while an Interception Proxy is introduced by the router with out knowledge or effort by the HTTP Client such as a browser.
-
A Replica Cache is maintained at the Surrogate (or a Reverse Proxy or a Load Balancer). A Surrogate is defined in RFC 3040 as “A gateway co-located with an origin server”.
Other than these there may be application specific caches that operate behind the Origin Server to accelerate the content or computation.
Caching Controls
As defined by RFC 2616[1] HTTP 1.1 defines three ways in which cachebility of an object can be controlled in three basic ways,
-
Freshness defines the time period during which the object can be used with out checking its validity with the server (Weak Consistency).
-
Validation is used by the client and Proxy Server to verify that an object is still fresh. This is usually accomplished with the If-modified-since header (Strong Consistency).
-
Invalidation is usually a side effect of another HTTP request that passes trough the intermediary. For e.g HTTP methods like PUT POST and DELETE will invalidate the corresponding GET request caches.
How the Caching Works
The HTTP caching is defined in RFC 2616[1]. Caching requires that either the HTTP client go through an intermediary called an HTTP Proxy Server or that the origin server delegates the first processing of request to a co-located server called a Surrogate. Once the request reaches an intermediary that can cache, the intermediary looks at the URL being requested, and the response being generated, and determines if the response could be cached. This decision depends on a number of variables like the cache-control directives defined in the request and the response, The expiry time and last modified time of the object in the response, If the object requires authentication for access, and the capacity of the intermediary to cache. If the object can be cached the intermediary caches the object and returns the object to the requesting HTTP client. When an HTTP client request the same object again, the cache intermediary fetches the previously cached object and returns the same along with some meta information as to the freshness of the cached object.
In the below diagram, the browser sends a request to a Proxy Server. This request is processed the
Proxy Server first. The Proxy Server forwards the request to Surrogate, which in turn passes it to the
Origin server which serves the request.
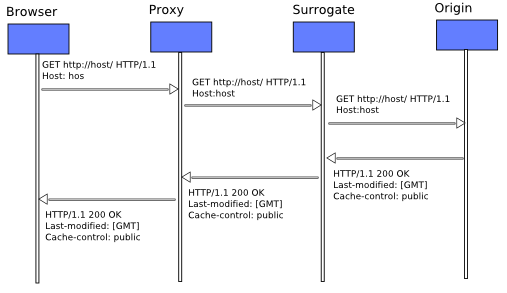
The second time the request comes to the Proxy Server, it finds the requested object in the cache. However before returning the cache, It validates the freshness of the copy with the Surrogate Server. For the Surrogate server however, this validation check may not be necessary (depending on its configuration). Because it is co-located with the Origin Server, it may have other mechanisms to receive updates when a cached object becomes stale. Thus the Surrogate server returns a 302 (use local copy) response to the Proxy Server, which in turn serves the now validated object to the HTTP client. Note that a Surrogate server or a Proxy Server is not necessary for the normal operation of HTTP. However they make it faster by reducing the traffic between the client and the server.
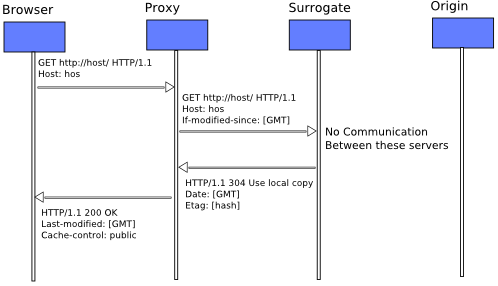
The Proxy Server is free to contact any data-store that have a valid copy of the requested file. It is also free to route the request through another intermediary that may have the requested object in cache or claim ownership over the named object. This survey explores the protocols through which the Proxy Server can find out about the intermediaries that may contain the requested object. The difference between the Proxy Servers as intermediaries and the Surrogate is that the Proxy Servers are allowed to contact only other Proxy Servers using the distributed caching protocols. The communication between the Proxy Servers and the Surrogates are limited to pure HTTP protocol. (As far as the Proxy Server or the HTTP client is concerned there is no difference between a Surrogate Server and an Origin Server.)
Protocols
Internet Cache Protocol
ICP was originally developed as a component of the Harvest cache project. Caching with ICP is documented in RFC 2186[2] and RFC 2187[15]. It is an extremely lightweight protocol aimed at cooperation of hierarchical cache systems. It works by sending icp-query messages containing the URL payload to its peers, Any peer that has the URL payload in its cache sends the originator an icp-hit. Any cache that does not have the URL in its cache sends an icp-miss. The miss is typically ignored, but the cache that first responded with icp-hit is selected as the peer through which the request will be routed. If none of the peers responded with a hit with in a timeout period, the same is sent to the defined parents of the cache group. In this case if a parent responds with a hit, that parent is selected for routing the request. Else the parent that responded first with an icp-miss is used as the route to forward the request. Typically ICP is used in hierarchical networks inside organizations. Various departments would host their own ICP enabled Proxy Servers feeding to the main internet facing Proxy Server.
Advantages:
-
Redundant caching: The same response is cached in all the proxies that acted as intermediary to the request. This effectively means that the parent and the child caches involved store the same response.
-
Joining and leaving a group is very simple. and it is very resilient to crashes of members in the group.
Disadvantages:
-
Latency to contact peers
-
A somewhat large amount of bandwidth is consumed by the broadcasted icp-queries, misses and hits.
-
Since the URL is the only payload, ICP cannot support the HTTP mechanisms like vary headers, content encoding headers and language headers which are used to support varying responses for the same URL.
-
Several caches with differing versions may respond with a HIT resulting in breakage of consistency
Cache Array Routing Protocol
CARP is a hash function based Proxy selection mechanism. It is not a communication protocol. It was first implemented in the Microsoft Proxy Server. Unlike ICP it uses a name space partitioning scheme, and allows content to be cached in the network without duplication. The URL name space is split into different regions using a hashing algorithm based on the number of participating caches, and the client browser computes address of the cache that owns the content using a published algorithm. This algorithm is published in a common location (called Proxy Auto Config file) and is used by the client browsers to determine the Proxy to route through for a given URL. This PAC file may instead discovered by using a protocol called WPAD[47].
Advantages:
-
The content is not duplicated within the network
-
The protocol does not require communication between the members except as a heartbeat check to make sure the members are alive.
-
The protocol is inherently suited for a flat name space setup with a large number of proxies facing the internet and the client browser choosing any based on the URL
Disadvantages:
-
It requires the maintaining of sibling relationships in all proxies to effectively partition the name space.
-
Addition or removal of a cache from the system causes some of the cached objects to become invalid.
-
Some caches can become asymmetrically loaded compared to others.
Cache Digests
In this protocol, the Proxy Servers periodically exchange a compressed digest of all URLs in their cache. The proxies can then use these digests to determine who has the requested object in their cache and retrieve the object from that peer. Cache digests are exchanged using standard HTTP protocol where a peer requests the digest from a standard URL hosted on the Proxy Server. The cache digest has to be periodically renewed to take into account the expiration of cached resources. The standard HTTP cache headers are used to indicate until what time the cache digest may be valid. Cache digests are created by applying using Bloom Filters on the set of cached URLs with the Proxy Server.
Advantages:
-
Each Proxy Peer has a fairly accurate ‘world view’ and knows who has cached what. This helps cut down unnecessary routing.
-
The protocol is implemented over HTTP which makes it easier for caches with in and outside firewalls to co-operate
-
Absence of query|hit|miss messages makes the bandwidth overhead lower than ICP. Also it makes the routing delay much lower
Disadvantages:
- Caching of new objects and eviction of older ones causes the bloom filter to rapidly increase the rate of false positives. When this happens, the bloom filter has to be regenerated as it offers no option to delete items from the set.
Summary Cache
Summary Cache[43] is very similar to Cache Digests. But it uses a Counting Filter rather than a Bloom Filter to create the URL digest. Due to this change, the problem with cache eviction is removed as Counting Filter supports deletion of objects from the set.
Advantages:
- Can support cache eviction easily compared to Cache Digests
Disadvantages:
- The size of digests exchanged becomes quite large compared to Cache Digests because of the addition of counting bits.
Hyper Text Caching Protocol
This is a protocol that was proposed as a replacement for ICP. It is a protocol for discovering caches and cached data, managing caches and monitoring cache activity. The major difference with ICP is that HTCP query includes the full HTTP request headers and the HTCP replies include the full response headers. This allows it to cater to the vary headers and other objects identified using different headers. [20] gives a good explanation of features of HTCP.
Advantages:
-
Supports pushes for letting siblings know of significant events such as cache object expiry
-
Supports location of cached objects based also on the headers rather than just the URLs. This helps in support of vary headers of HTTP.
-
Supports third party replies of the form ‘I know who has this cache object.’ which helps the cache hierarchy scale better.
Disadvantages:
- Redundant caching of objects
Web Cache Control Protocol
WCCP is used to transparently detect and redirect web traffic from a router to the WCCP enabled Proxy Servers. The protocol defines the communication between the Proxy Server and the router. The WCCP based caching is used to implement intercepting caches for HTTP requests. WCCP is a first level protocol where it only helps in getting the request to be redirected to the cache. It does not define further communication between the Proxy Servers.
Advantages:
- It is implemented as a mechanism for Interception Proxy (proxying with out the client’s knowledge)
Disadvantages:
- Requires specialized equipment (routers that can talk WCCP, Operating systems that has GRE tunnels)
Internet Content Adaptation Protocol
ICAP[8] is a lightweight protocol for HTTP based RPC call. This can be used to offload cache fetching to separate dedicated ICAP servers. When a query comes in, the an ICAP request is made to one of the ICAP servers to find if they have a copy of the requested object. If it has, that copy is retrieved and used instead of using the local cache.
Advantages:
-
Offloads a significant portion of work from the Proxy Server
-
Multiple Proxy Servers can use the same ICAP Server and avoid duplicate caching
Disadvantages:
-
It requires another hop for retrieving cached objects making the whole thing slower than other solutions.
-
It just hands off the problem of co-ordination to another Server, rather than solving it. More over while Co-operating cache protocols are well understood, not much research has gone into Cooperation between ICAP Servers.
Cache Group Management Protocol
CGMP[31] is used by Adaptive Cache meshes to create and maintain groups of caches. The caches are arranged as overlapping multi-cast groups. The membership is usually determined by feedback and voting. [34]Each node listens to multi-cast signals, and tries to join multiple groups. They send votes to every other node in the group. The vote signal decreases with distance (based on hops, delay, cost etc) and becomes negative at a certain point. Each node sums the votes from all other nodes in any group G, the sum determines the fitness of the node N in the group G. New nodes bid for the existing members to change their votes. Members average bids to satisfy the majority. If two nodes are members of one group, they send strong negative votes against each other for another group. This helps create efficient global connectivity.
Content Routing Protocol
CRP[31] is used by Adaptive Cache meshes to look up cached content in overlapping meshes organized using CGMP[34]. It relies on multi-cast groups and URL tables to lookup content. When a query is received, the current server is checked first. If not found, it is routed to the groups that the server is member of. Each cache maintains a list of cached URL indices which are exchanged periodically with other caches in the group. The URL index updates are transmitted other group in using a distance vector to limit the spread. The longest match in the routing table is selected as the next hop. If none found, the request is forwarded to the server directly.
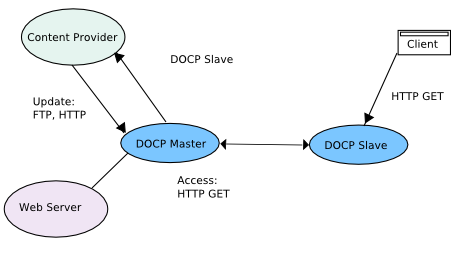
Distributed Object Consistency Protocol
DOCP[49] is an extension over HTTP to provide more caching facilities. It provides for DCOP master that act as surrogates and DOCP slaves which act as Proxy Servers. The DCOP slaves request for leases on objects that DOCP master stores, so that they get notifications when the objects change. The leases expire in a fixed amount of time.
Advantages:
-
Since Servers issue invalidation, the consistency guarantee is stronger
-
Lesser traffic compared to non-notification protocols
-
Reduced Load
Disadvantages:
- Extends HTTP, so while it can inter operate with non DOCP caches, it requires other caches and servers to be DOCP enhanced to be able to work efficiently.
Hash based Query Caching
In HQCM[46], Hashing is used to find the node to which a query should be sent to. Each node holds the objects being cached, and the past history of requests from other nodes for URLs. Thus a node can find the current holders of an object with a single query.
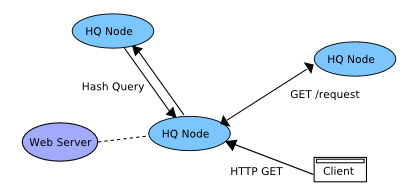
Advantages:
- Can get the route to an object with a single query
Disadvantages:
- Each HQ node needs to maintain a history of past accesses by all other nodes to the URLs that the node is caching. This is costly in terms of implementation and resources.
Caching and Replication for Internet Service Performance
CRISP[20] is a caching service with a central caching map server. When a client requests an object it is first searched in the local cache, if not found, the requested URL is looked up using the central map server. The map server will return the address of the cache holding a valid copy if one was found. If it was found, the local node will retrieve it and return it to the client. If it was not available in the CRISP network, then the origin server is contacted and the requested object is retrieved. An update is also issued to the map server to keep it informed of the newly cached object.
Advantages
-
Easy to lookup objects
-
No redundant caching
-
No management overhead
Disadvantages
-
Central point of failure
-
High traffic to map server due to addition and deletion of object mappings
HTTP Notify
HTTP Notify [22] is a new draft for a notification mechanism for object updates from Origin Servers to Proxy Servers. With this protocol the Proxy Server can indicate in the header ‘Proxy-features’ that it is willing to accept notification along with the GET request for any URL that the Proxy Server wishes to monitor. The Server indicates its willingness to keep the Proxy notified using ‘Cache-control’ header parameter ‘notify’. When the specified object changes at the Server, the notification gets sent to the corresponding Proxy Server using a new method ‘NOTIFY URL’
Cache Channels
Cache Channels[10] are out-of-band event propagation channels from HTTP Origin Servers to subscribing caches. Channels are published using Cache-Control channel extension. A channel makes available events including staleness of objects in the Server. This information can be used by Cache Servers.
Piggy Back Cache Validation
In PCV[23], When ever the Proxy Server has a chance to communicate with the Server, it piggy backs a list of resources that it has in cache, that came from the same Server. The Server in turn returns back a list of invalid resources. This approach is implemented either by adding a new header type for the list of resources to be checked for validity or by trailing a list of HEAD requests of the resources that needs to be checked for validity in the same keep-alive request.
Advantages:
- Reduced Traffic
Disadvantages:
- Higher load on the Server for each request
###Piggy Back Server Invalidation
In PSI[24], the server keeps track of the clients access histories. Each time a client connects, Server fetches the list of resources that the client has accessed in the recent past, and piggybacks in the response those resources that have changed since the clients last access. This protocol is complementary to PCV[23] that we have discussed above.
####Advantages:
- Reduced Traffic
Disadvantages:
- Stateful Server - makes the Server more complex.
HTTP Distribution and Replication Protocol
DRP[25] is typically used by Surrogates to keep the cache fresh. The protocol makes available an index containing the state of all documents in a Server. Thus by downloading this index at periodic intervals, the client is able to determine which resources need to be updated. The validity period of the index is determined by the standard cache headers.
Relais Protocol
Relais[50] is based on a distributed index. Each node maintains a copy of the shared directory or the index. When ever an object is inserted or deleted from the shared directory, notifications are sent to all the members of the group getting them to update their copies also.
Advantages:
-
No lookup latency
-
Consistency guarantee (monotonic reads)
-
Fault tolerant
Disadvantages:
- Needs a lot of memory
Library Cache Auditing Protocol
LCAP[45] is the protocol used by LOCKSS[45] to coordinate among various replicas. It specifies mechanisms to ensure that a cached content is valid and correct. It does this by having lots of redundant copies and conducting elections on URLs among the replicas. Each replica broadcasts a hash of the content cached by it, and other replicas may agree or disagree with it. If it fails, then the replica takes steps to rectify the damage.
Advantages:
-
Fault Tolerant
-
Resistant to attacks
Disadvantages:
-
This is not a generic caching protocol
-
Redundant caching.
-
Heavy traffic due to polling
References
[1] RFC 2616 Fielding, et al. http://www.w3.org/Protocols/rfc2616/rfc2616-sec13.html
[2] RFC 2186 http://www.ietf.org/rfc/rfc2186.txt
[3] RFC-DRAFT http://icp.ircache.net/carp.txt
[4] RFC http://www.squid-cache.org/CacheDigest/cache-digest-v5.txt
[5] RFC 2756 http://www.faqs.org/rfcs/rfc2756.html
[6] RFC-DRAFT http://tools.ietf.org/id/draft-wilson-wrec-wccp-v2-01.txt
[7] RFC 3040 http://www.faqs.org/rfcs/rfc3040.html
[8] RFC 3507 http://www.icap-forum.org/documents/specification/rfc3507.txt
[9] RFC 3229 http://www.ietf.org/rfc/rfc3229.txt
[10] cache-channels http://ietfreport.isoc.org/all-ids/draft-nottingham-http-cache-channels-01.txt
[11] HTTP 1.0 http://www.ietf.org/rfc/rfc1945.txt
[12] HTTP 1.1 http://www.ietf.org/rfc/rfc2068.txt
[13] caching problems http://www.networksorcery.com/enp/rfc/rfc3143.txt
[14] cache-protocols http://www.web-cache.com/Writings/protocols-standards.html
[15] ICP Applications http://www.ietf.org/rfc/rfc2187.txt
[16] http://www.csd.uoc.gr/~hy558/papers/wang99survey.pdf
[17] http://www.isoc.org/inet98/proceedings/1k/1k_1.htm
[18] http://forskningsnett.uninett.no/arkiv/desire/sumreport/sumreport.html
[19] http://2002.iwcw.org/papers/18500200.pdf.
[20] http://www.squid-cache.org/mail-archive/squid-users/199807/0010.html
[21] CRISP http://www.cs.duke.edu/ari/cisi/crisp-recycle/crisp-recycle.html
[22] HTTP Notify http://www.w3.org/TR/WD-proxy
[23] PBV http://www.usenix.org/publications/library/proceedings/usits97/krishnamurthy.html
[24] PBI http://www.research.att.com/~bala/papers/psi-www7.ps.gz
[25] HTTP Distribution and Replication Protocol http://www.w3.org/TR/NOTE-drp-19970825.html
[26] Push Caching http://www.eecs.harvard.edu/~vino/web/hotos.ps
[27] Push Caching Protocol http://www.cs.uwaterloo.ca/~alopez-o/cspap/cache/Overview.html
[28] http://www.dstc.qut.edu.au/MSU/staff/povey/papers/dcache.ps
[29] http://www.codeontheroad.com/papers/HarvestCache.pdf
[30] http://www.iwcw.org/1998/25/3w3.html
[31] Web Caching and Its Applications - Nagraj http://books.google.com/books?isbn=1402080492
[32] Cachemesh http://workshop97.ircache.net/Papers/Wang/wang.txt
[33] http://sys192.cs.washington.edu/Related/xdcs.ps
[34] http://irl.cs.ucla.edu/AWC
[35] http://www.cs.rice.edu/Conferences/IPTPS02/176.pdf
[36] http://www.ics.uci.edu/~taylor/documents/2002-REST-TOIT.pdf
[37] http://research.microsoft.com/~antr/PAST/squirrel.pdf
[38] http://www.coralcdn.org/overview/
[39] DSHT http://www.coralcdn.org/docs/coral-iptps03.pdf
[40] http://en.wikipedia.org/wiki/Small_world_network
[41] http://code.google.com/p/dijjer/
[42] http://www.howardissimo.com/notorrent/
[43] http://www.cs.wisc.edu/~cao/papers/summary-cache/
[44] http://www.hpl.hp.com/techreports/1999/HPL-1999-109.ps
[45] http://www.sunlabs.com/features/lockss/index.html
[46] HQCM http://ieeexplore.ieee.org/xpl/freeabs_all.jsp?arnumber=801214
[47] WPAD http://www.ietf.org/proceedings/99nov/I-D/draft-ietf-wrec-wpad-01.txt
[48] http://www.dyncorp-is.com/darpa/meetings/ngi98oct/Files/Zhang%20NGI-final.ppt
[49] DOCP http://www.hpl.hp.com/techreports/1999/HPL-1999-109.html
[50] http://www-sor.inria.fr/projects/relais/index.html.en