Rahul Gopinath is a lecturer at the University of Sydney. His focus is static and dynamic analysis of software. He received his Ph.D. in 2017 from the School of EECS at Oregon State University, and did his postdoc at CISPA Helmholtz Center for Information Security, Germany. The following is a summary of his research.
Cybersecurity
My work is focused on fuzzing software systems. Fuzzing is essentially about evaluating how a software system responds to unexpected and possibly invalid inputs. The question is, can you make the system under fuzzing behave in an unexpected or unforeseen manner? If a system correctly rejects all invalid inputs and behaves correctly under valid inputs, we say that the system is robust under fuzzing. Fuzzing a system requires relatively little manual input, and fuzzing a system before its release can help uncover vulnerabilities before it is exposed to the wider world.
Our work produced the fuzzing book which is an accessible resource for students and practitioners new to fuzzing.
 It takes the student through writing simple fuzzers that generate random inputs without any information or feedback from the program to writing complex fuzzers that analyze the system under fuzzing for information about the expected inputs and incorporate the feedback from previous runs to guide further fuzzing.
It takes the student through writing simple fuzzers that generate random inputs without any information or feedback from the program to writing complex fuzzers that analyze the system under fuzzing for information about the expected inputs and incorporate the feedback from previous runs to guide further fuzzing.
One of the challenges in fuzzing is how to reach deep code paths. In particular, many systems accept multilayered inputs such as an HTTP request that wraps a JSON object, which in turn encodes an RPC call, which may, in turn, encode a custom data structure. For such inputs, traditional fuzzers rarely reach beyond the first layer. The problem is that traditional fuzzers rely on coverage to decide how to proceed. When a fuzzer is faced with a program with a complex input structure, coverage is of little help beyond producing simple values as the paths explored are the same for simple or complex inputs. This means that one needs a better way of producing complex inputs than traditional coverage guided fuzzing.
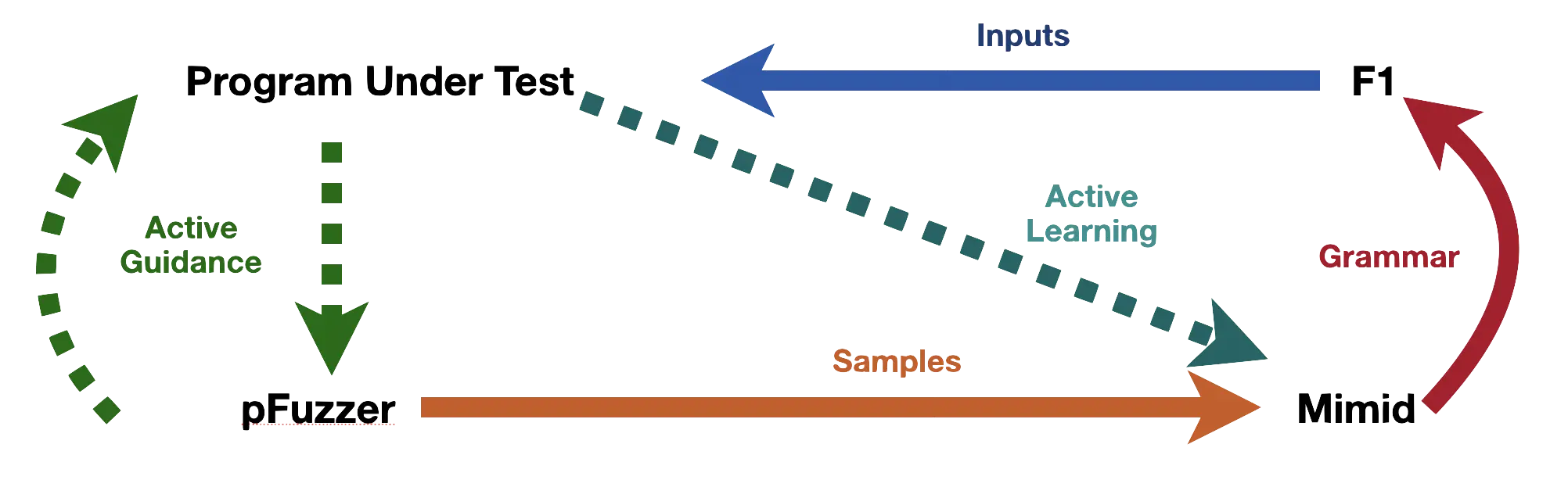
Our first research was toward generating complex valid inputs when faced with a parser so that we can get to the next level. We found that traditional approaches such as symbolic execution do not work well due to path explosion when faced with parsers. We invented a fast and lightweight approach called Pygmalion that iteratively corrects a generated input prefix which ultimately leads to valid inputs. Our approach is applicable both for single pass parsers (PLDI 2019) as well as for parsers with a lexical analysis stage (ISSTA 2020). Our technique is applicable even for instrumentation-less systems such as embedded systems and remote systems.
While Pygmalion can get us valid inputs faster than traditional methods, it is limited to overcoming the first layer parser. While Pygmalion is fast, it still needs to run the program under fuzzing once per input character, which is comparatively expensive if one wants to produce a large number of valid inputs. Hence, we invented a technique called Mimid that can infer the input structure expected by a given parser as a context-free grammar from the dynamic analysis of the program run (FSE 2020). In particular, Mimid covers the entire spectrum of parsers from ad hoc handwritten parsers to modern parser combinators, and represents a significant advancement in the field.
Given such a grammar, the problem reduces to how one can generate inputs fast from a context-free grammar. The problem at this point was that the available grammar-based fuzzers were too slow. Hence, we adapted ideas from programming language implementation, and virtual machine optimization to build our F1 grammar fuzzer which is effective and efficient and can produce millions of inputs per second.
While fuzzers are effective in quickly identifying failure conditions using surprising inputs, the inputs produced
by these tools can often be huge, and incomprehensible to the developer.
Hence, test case reduction (often variants of delta debugging) is often used to reduce the test case to a minimal
input, such strings still fail to inform the developer as to what went wrong.
Even worse, a casual inspection of many such test cases can often suggest an
incorrect hypothesis. We invented
a technique called DDSET that identifies the parts of the input that caused the failure, and abstracts
away everything else. The failure representations (we call these
evocative patterns) produced by DDSET (e.g. ((<expr>)) when
the error is caused due nested parenthesis)
are precise and easy to understand.
Our work was presented at ISSTA 2020, and received the ACM SIGSOFT Distinguished Paper award.
The evocative patterns thus produced represent a specialization of the base grammar of the input. In our paper at ICSE 2021, we show how, given the base grammar and the evocative pattern corresponding to a failure, one can produce the corresponding specialized context-free grammar which guarantees that the evocative fragment is present in all inputs produced from the specialized grammar at least once. We also show how to combine such evocative patterns using all logical connectives — conjunction, disjunction, and negation — forming evocative expressions that represent a specialized context-free grammar.
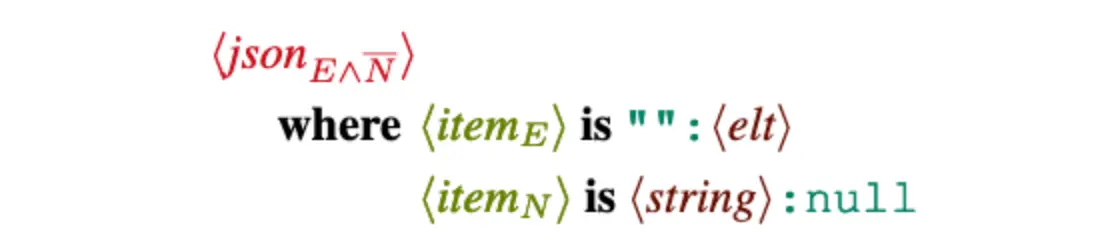
The example above shows a simple evocative expression that specializes a base JSON grammar. The corresponding evocative grammar guarantees that the inputs produced will have at least one empty key (the first evocative pattern in the where clause), and no null key values (the second evocative pattern in the where clause, negated). Second, it also guarantees that the evocative grammar produced will be able to successfully parse any input that conforms to these specifications (or the grammar when used as a producer can produce any such input). While the evocative patterns can be written by hand, they can also be mined from existing bugs by simply using the DDSET algorithm. These evocative expressions can not only be used as precise generators but also as supercharged semantic pattern matchers similar to Semgrep.
Test suite and test case effectiveness
I have also worked on empirical evaluation of the effectiveness of different coverage techniques. Our initial work (ICSE 2014) towards addressing the shortcomings of mutation analysis found that statement coverage, rather than branch or path coverage is a better measure of mutation score, and hence the quality of a test suite. This was substantiated by extensive examination of over 200 real-world projects of various sizes, and this was notably different from the prevailing wisdom which claimed that branch and path coverage was obviously better.
We were also the first (and to date, the only ones) to find evidence that mutation score as well as coverage is inversely related to the residual defect density of the program (FSE 2016). That is, the number of live mutants remaining is related to the actual bugs remaining in the program. Finally, our recent work (ASE 2020) clarifies the relationship between test suite size and coverage. It settles a long standing debate about how to interpret the effect of test suite size, and shows how to correctly account for the suite size in empirical evaluations.
Mutation analysis
My primary focus during my PhD was mutation analysis of programs, and especially how to make mutation analysis a workable technique for real-world developers and testers.
Mutation analysis is a method of evaluating the quality of software test suites by introducing simple faults into a program. A test suite’s ability to detect these mutants, or artificial faults, is a reasonable proxy for the effectiveness of the test suite. While mutation analysis is the best technique for test suite evaluation we have, it is also rather computationally and time intensive, requiring millions of test suite runs for even a moderately large software project. This also means that mutation analysis is effectively impossible to use by developers and practicing testers working on real-world problems, and who need to evaluate whether their current test suites are adequate. Unfortunately, most of the research done in mutation analysis has been done on a small number of subject programs, small in size, and that have test suites with high coverage and adequacy – something that is a rarity in real-world development (at least at early development stages).
My research (ISSRE 2014) evaluated whether the faults produced by mutation analysis were representative of real faults. Our examination of over 5,371 projects in four different programming languages found that the faults used by mutation analysis are rather simplistic in practice compared to real-world bugs (in terms of the size of code change).
As an initial step towards reducing the computational requirements of mutation analysis, I investigated techniques used for mutation analysis, and invented a new algorithm (ICSE 2016 abstract) for faster mutation analysis, taking advantage of redundancy in execution between similar mutants. Further, I was able to identify how combinatorial evaluation could be used for evaluating equivalent mutants (ISSRE 2015).
Next, I compared the effectiveness of current techniques for reducing mutants to be evaluated such as operator selection and stratum based sampling and found that they offer surprisingly little advantage (less than 10% for stratum sampling and negative for operator selection) compared to simple random sampling in multiple evaluation criteria. My research (ICSE 2016) comparing the effectiveness of the theoretical best mutation selection methods with random sampling found that even under oracular knowledge of test kills, mutation selection methods can at best be less than 20% better than random sampling, and are often much worse. Interestingly, there is no such limit on how the amount of efficiency that can be achieved by the addition of new operators. This discovery suggests that effort should be spent on finding newer and relevant mutation operators rather than removing the operators in the name of effectiveness. This research also effectively settled the long standing debate on the utility of mutation reduction strategies such as operator selection in favor of random sampling.
Finally, we were able to conclusively prove the coupling effect theoretically, as well as quantify its impact empirically (ICST 2017). The coupling effect is one of the corner stones of mutation analysis, and our research provided the much needed clarification on the relation between simple faults that mutants represent and higher order faults that are common in real world programs.
Practice
My interest in the quality of programs is informed by a wealth of practical knowledge from the Industry. Before joining the Ph.D. program, I worked in the software industry as a developer for ten years, where I was part of the web and proxy server development teams at Quark Media House, and Sun Microsystems. My primary area of interest was the web caches, particularly the distributed caching systems and protocols. I participated in the OpenSolaris effort, where I was the maintainer of multiple open source packages. I have also contributed to the Apache HTTPD project, in core and mod_proxy modules. During my Ph.D., I worked at Puppet Labs where I contributed extensively towards the functionalities in the Solaris Operating system, and at Galois where I contributed to the visualization of effectiveness of one of the vulnerability mitigation approaches.
IMPORTANT: If you are my student, and facing any sort of difficulties, please do contact me. I will be happy to talk to you, and help you in any way.